数据之海,智能之帆 机器学习与互联网数据服务的共生演进

在人工智能的浪潮中,机器学习(Machine Learning, ML)已从一个前沿概念演变为驱动当代社会数字化转型的核心引擎。无论是精准的推荐系统、智能的语音助手,还是自动驾驶与医疗影像分析,其背后闪耀的智慧,都深深植根于一个看似平凡却至关重要的基础——数据。而互联网,作为人类有史以来规模最大、增长最快的数据生成与交互平台,其提供的数据服务已成为机器学习赖以生存和发展的“血液”与“燃料”。二者之间,正构建着一场深刻而持续的共生演进。
一、机器学习:以数据为师的智能范式
机器学习的本质,是让计算机系统能够从数据中自动“学习”规律和模式,并利用这些学习成果进行预测或决策,而无需依赖显式的、硬编码的程序指令。这一过程通常包含数据收集、预处理、模型训练、评估与部署等多个环节。其中,数据的质量、规模和多样性,直接决定了模型的上限。
- 数据是知识的载体:模型无法凭空创造知识,它必须从标注好的图像中学习“猫”的特征,从海量的文本对话中理解语言的逻辑,从历史交易记录中洞察用户的行为偏好。没有数据,机器学习就如同无米之炊。
- 规模与复杂性驱动进步:深度学习等现代ML技术的突破,很大程度上得益于大规模数据集(如ImageNet)的出现。更大量、更多维的数据使得模型能够捕捉更细微、更复杂的模式,从而在图像识别、自然语言处理等领域实现从“可用”到“卓越”的跨越。
二、互联网数据服务:机器学习的数据沃土
互联网不仅连接了全球数十亿的用户与设备,更在每分每秒中产生着天文数字般的数据——搜索查询、社交媒体动态、电子商务交易、传感器读数、流媒体内容等。围绕这些数据的收集、处理、存储与提供,形成了庞大的互联网数据服务生态,这为机器学习提供了前所未有的养料。
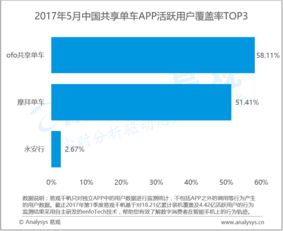
- 海量数据来源:互联网平台是天然的、持续的数据生产工厂。例如,电商平台拥有完整的用户浏览、点击、购买链路数据;社交媒体积累了丰富的用户关系、内容互动与情感表达数据;搜索引擎则处理着全球用户的实时意图数据。这些高价值、场景化的数据是训练行业专用模型的基石。
- 数据服务的专业化:为了赋能机器学习,互联网公司及专业数据服务商构建了复杂的数据基础设施和服务:
- 数据采集与清洗服务:提供合规的网络爬虫、API接口、数据去重、异常值处理等工具与服务,将原始、杂乱的网络数据转化为可用于训练的结构化、高质量数据集。
- 数据标注与增强平台:对于监督学习,高质量标注至关重要。众多平台提供图像框选、语义分割、文本分类等众包或自动化标注服务,并可通过数据合成、变换等技术进行数据增强,以有限数据创造更大价值。
- 开源数据集与模型库:如Kaggle、Google Dataset Search、Hugging Face等平台,汇集了来自全球的研究机构和公司发布的多样化数据集与预训练模型,极大降低了ML研究与应用的入门门槛,促进了社区协作与知识共享。
- 云计算与MLaaS(机器学习即服务):AWS、Google Cloud、Azure等云服务商提供从数据存储、处理到模型训练、部署的一站式ML管道,使开发者无需自建昂贵基础设施,即可利用强大的算力处理互联网规模的数据。
三、共生关系与挑战
机器学习与互联网数据服务之间,已形成紧密的“需求-供给”循环和“能力-反哺”闭环。
- 循环增强:机器学习算法需要互联网数据来提升性能;而更智能的算法(如更精准的推荐、更高效的搜索)又能改善用户体验,吸引更多用户参与,从而产生更多、更优质的数据,进一步驱动模型迭代升级。
- 反哺生态:基于ML的数据分析工具,本身也成为了优化互联网数据服务的关键。例如,利用NLP技术自动分类和标签化内容,利用计算机视觉审核违规图片,利用预测模型优化数据存储和传输策略。
这种深度依赖也带来了不容忽视的挑战:
- 数据隐私与安全:大规模收集和使用个人数据引发了严峻的隐私保护问题。各国法规(如GDPR、CCPA)对数据合规性提出了严格要求。如何在保障用户隐私的前提下,有效利用数据进行机器学习(如通过联邦学习、差分隐私等技术),是行业面临的核心课题。
- 数据偏见与公平性:互联网数据并非客观中立的,它可能反映了现实社会中的偏见与不平等。用此类数据训练的模型,可能会放大或固化这些偏见,导致算法歧视。确保数据集的代表性和公平性,是构建可信AI的关键。
- 数据质量与“数据荒漠”:并非所有领域都有丰富、易得的互联网数据。在工业制造、尖端科研、特定医疗领域等,高质量标注数据可能非常稀缺,形成“数据荒漠”,制约了ML在这些关键领域的应用。
四、未来展望
机器学习与互联网数据服务的融合将更加深入:
- 实时化与流式学习:随着5G和物联网的普及,对实时数据流进行在线学习和即时推理的需求将激增,推动数据服务向更低延迟、更高吞吐的方向演进。
- 多模态数据融合:文本、图像、语音、视频、传感器数据等多模态信息的联合学习将成为趋势,这要求数据服务能够提供高质量、对齐的多模态数据集和处理能力。
- 隐私计算成为基础设施:以安全多方计算、同态加密、可信执行环境为代表的隐私计算技术,有望在保护数据隐私的前提下,打破“数据孤岛”,实现数据价值的合规流通与协同计算。
- 合成数据兴起:在数据稀缺或隐私敏感的领域,利用生成式AI(如GANs、Diffusion Models)创造高保真合成数据,将成为补充甚至替代真实数据的重要途径。
总而言之,机器学习的光芒,正是在互联网数据服务的广袤土壤上绽放。数据是起点,智能是方向。面对机遇与挑战并存的前路,唯有在技术创新、伦理规范与法律监管之间寻求平衡,才能驾驭好这艘由数据之海托起的智能之帆,驶向更加高效、公平和可持续的未来。
如若转载,请注明出处:http://www.epiuu.com/product/36.html
更新时间:2026-06-18 14:01:46